Macedonian LLM
🐂 domestic-yak, a Macedonian LM
🌟 Summary
- Language: Macedonian (
mk) - Base Model: domestic-yak-8B
- Instruct Model: domestic-yak-8B-instruct
- GGUF Model: domestic-yak-8B-instruct-GGUF
- Dataset: ~100k samples across multiple categories (Question answering (QA), chat-like conversations, reasoning, essays, and code) consolidated from translating publicly available datasets and custom synthetic data.
📋 Overview
After collecting the Macedonian corpus, we asked ourselves: why not create an LLM specifically for the Macedonian language? Inspired by recent efforts, such as Nikola Trajkov's creation of the first Macedonian LLM in June 2024 and Aleksa Gordic's YugoGPT in January 2024, we decided to create our own model. In retrospect, we think we made the right decision as this was a super cool and useful learning experience. Going through the entire process end-to-end taught us a lot more than theoretical knowledge ever could. We hope you’ll find the model just as useful as we found the journey rewarding. The result from this journey is domestic-yak-8B, a model that is currently the best in the 8B parameter range but also outperforms larger models like Llama-3.3-70B-Instruct on three benchmarks.
To support fair evaluation, we also created/translated a unified benchmarking framework for Macedonian LLMs (more details available in the Macedonian LLM Eval page).
The model underwent a two-stage training process:
- Continued Pretraining: Built upon Llama-3.1-8B-Instruct, the model was pretrained on the deduplicated version of our Macedonian corpus (1.6 billion words) for 1 epoch.
- Supervised Fine-Tuning: Fine-tuned using a dataset of 100k samples covering diverse tasks such as question-answering, multi-turn conversations, reasoning, math, code, and synthetic examples. This stage consisted of 3 epochs.
The decision to use Llama-3.1-8B-Instruct as the base model was informed by its strong performance in our benchmarks as of January 5, 2025, making it a great starting point. We plan to share more technical details, including configurations, resources, training logs, and the rationale behind our choices, in an upcoming blog post. Currently we can't commit to a specific release date (as all three of us are juggling Master’s studies, thesis work, internships, and applications), but we will certainly try to release it as soon as possible.
📊 Results
Evaluating the model was stressful... what if all the effort leads to disappointing outcomes? Fortunately, domestic-yak-8B-instruct delivered as expected (hence its name). The model demonstrates performance on par with Llama 70B and even surpasses it in three benchmarks. It is also worth noting that this model is currently the best in the 8B parameter range. This achievement validates the high quality of our data and training methodology.
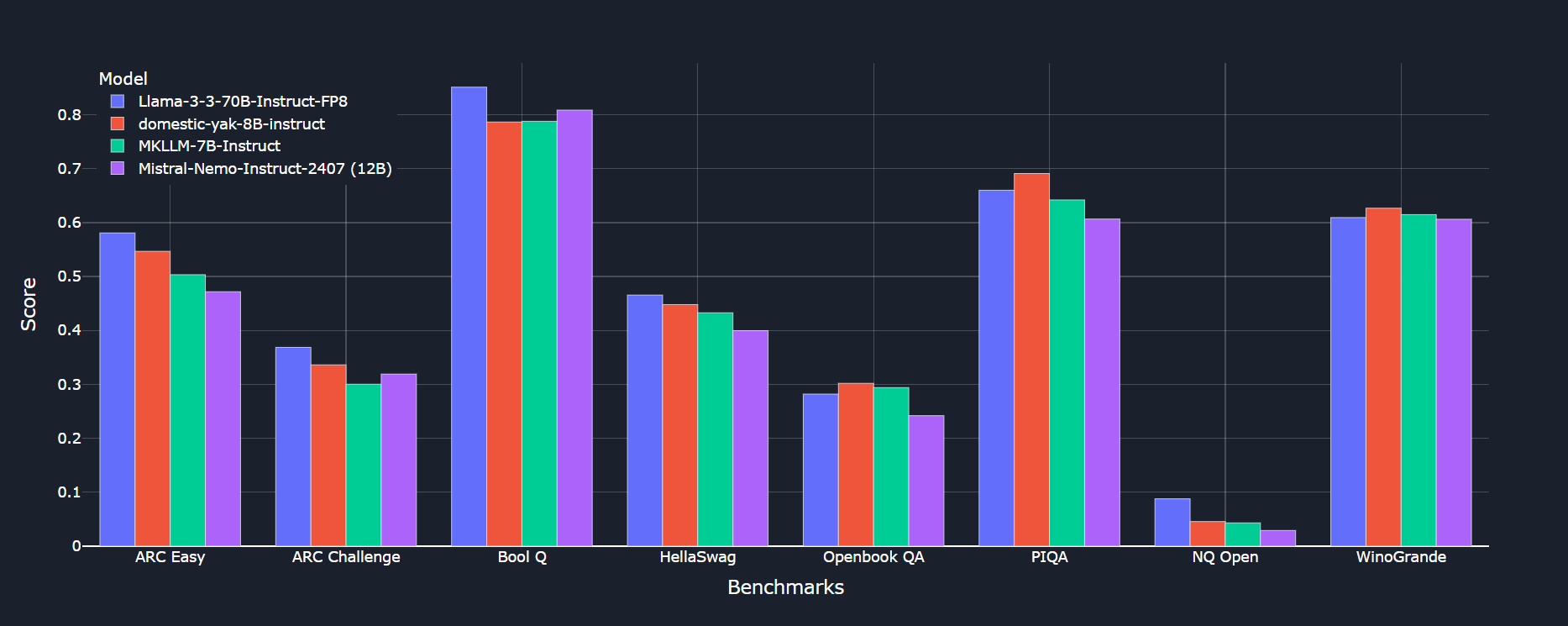
Quantitative evaluation is just one part of the story. We also conducted qualitative tests, interacting with the model to assess its ability to generate coherent and relevant responses in Macedonian. The results were satisfying: the model not only mastered the language's grammar but also demonstrated a natural and fluent style (we even learned some new words from it!).
Here’s a comparison showing the answers from Llama-3.1-8B-Instruct and domestic-yak-8B (base version):
-
Llama-3.1-8B-Instruct:
"Здраво! Секој пат кога го користиш оваа платформа, со тобе си во контакт со мојот систем на вештачка интелигенција. Мојот задача е да ти го обезбедам информативен и корисен одговор на секое прашање што можеш да ми го поставиш. Се нарекувам 'Асистент', и сум тука за да ти го правам живот полесен и интересниот. Што твоето прашање е?" -
domestic-yak-8B:
"Здраво, јас сум асистент дизајниран да обезбеди информации и одговори на прашања од корисниците. Можам да одговарам на широк спектар на прашања, од општи факти и информации до специјализирани прашања во различни области. Мојата цел е да обезбедам точни и корисни одговори, како и да го олеснам процесот на пребарување и да заштедам време за корисниците. Слободно постави ми го твоето прашање и ќе се обидам да ти помогнам."
For those who speak Macedonian, the difference is as clear as day; for everyone else, you’ll have to trust us on this one!
⚙️ Usage (for developers and researchers)
Pipeline automatically uses apply_chat_template which formats the input appropriately. The model was trained using the default Llama 3.1 format. The system prompt we used for fine-tuning the model is avaiable in the example below.
import transformers
import torch
model_id = "LVSTCK/domestic-yak-8B-instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "Ти си виртуелен асистент кој помага на корисници на македонски јазик. Одговарај на прашања на јасен, разбирлив и професионален начин. Користи правилна граматика и обиди се одговорите да бидат што е можно покорисни и релевантни."},
{"role": "user", "content": "Кој е највисок врв во Македонија?"},
]
outputs = pipeline(
messages,
max_new_tokens=256, # You can increase this
temperature=0.1,
)
print(outputs[0]["generated_text"][-1])
📬 Contact
For inquiries, feedback, or contributions, please feel free to reach out to the core team: